alertmanager
alertmanager可以放在远程服务器上
报警机制
在 prometheus 中定义你的监控规则,即配置一个触发器,某个值超过了设置的阈值就触发告警, prometheus 会推送当前的告警规则到 alertmanager,alertmanager 收到了会进行一系列的流程处理,然后发送到接收人手里
配置安装
wget https://github.com/prometheus/alertmanager/releases/download/v0.19.0/alertmanager-0.19.0.linux-amd64.tar.gz tar zxf alertmanager-0.19.0.linux-amd64.tar.gz mv alertmanager-0.19.0.linux-amd64.tar.gz /usr/local/alertmanager && cd /usr/local/alertmanager && ls
配置文件
cat alertmanager.yml
global:
resolve_timeout: 5m ##全局配置,设置解析超时时间
route:
group_by: ['alertname'] ##alertmanager中的分组,选哪个标签作为分组的依据
group_wait: 10s ##分组等待时间,拿到第一条告警后等待10s,如果有其他的一起发送出去
group_interval: 10s ##各个分组之前发搜告警的间隔时间
repeat_interval: 1h ##重复告警时间,默认1小时
receiver: 'web.hook' ##接收者
##配置告警接受者
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
##配置告警收敛
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
邮件接收配置
cat alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.163.com:25' #smtp服务地址 smtp_from: 'xxx@163.com' #发送邮箱 smtp_auth_username: 'xxx@163.com' #认证用户名 smtp_auth_password: 'xxxx' #认证密码 smtp_require_tls: false #禁用tls route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1m receiver: 'email' #定义接受告警组名 receivers: - name: 'email' #定义组名 email_configs: #配置邮件 - to: 'xx@xxx.com' #收件人
检查配置文件 ./amtool check-config alertmanager.yml
配置为系统服务
cat > /usr/lib/systemd/system/alertmanager.service <<EOF > [Unit] > Description=alertmanager > > [Service] > Restart=on-failure > ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml > > [Install] > WantedBy=multi-user.target > EOF
和prometheus 结合配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093 ##配置alertmanager地址
rule_files:
- "rules/*.yml" ##配置告警规则的文件
配置报警规则
报警规则的目录
/usr/local/prometheus/rules
/usr/local/prometheus/rules]# cat example.yml
groups:
- name: exports.rules ##定义这组告警的组名,同性质的,都是监控实例exports是否开启的模板
rules:
- alert: 采集器挂了 ## 告警名称
expr: up == 0 ## 告警表达式,监控up指标,如果等于0,表示监控的节点没有起来,然后进行下面的操作
for: 1m ## 持续一分钟为0就进行告警
labels: ## 定义告警级别
severity: ERROR
annotations: ## 定义告警通知怎么写,默认调用了{$labels.instance&$labels.job}的值
summary: "实例 {{ $labels.instance }} 挂了"
description: "实例 {{ $labels.instance }} job 名为 {{ $labels.job }} 的挂了"

配置的变量解释:
{{ $labels.instance }} #提取了up里的instance 值
{{ $labels.job }}
相同的报警名称即 alertname (根据配置文件 alert 归类)会被合并到同一个邮件里一并发出
告警的分配
分配策略,在报警的配置文件中设定
route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1m receiver: 'email'
告警分配示例
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'xxx@163.com'
smtp_auth_username: 'xxx@163.com'
smtp_auth_password: 'xxx'
smtp_require_tls: false
route:
receiver: 'default-receiver' ##定义默认接收器名,如果其他的匹配不到走这个
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname] ##分组设置
routes: ##子路由
- receiver: 'database-pager' ##定义接收器名字
group_wait: 10s ##分组设置
match_re: ##正则匹配
service: mysql|cassandra ##接收标签service值为mysql&&cassandra的告警
- receiver: 'frontend-pager' ##接收器名
group_by: [product, environment] ##分组设置
match: ##直接匹配
team: frontend ##匹配标签team值为frontend的告警
receivers: ##定义接收器
- name: 'default-receiver' ##接收器名字
email_configs: ##邮件接口
- to: 'xxx.xx.com' ##接收人,下面以此类推
- name: 'database-pager'
email_configs:
- to: 'xxx.xx.com'
- name: 'frontend-pager'
email_configs:
- to: 'xxx@.xx.com'
告警收敛
收敛就是尽量压缩告警邮件的数量,防止关键信息淹没,alertmanager 中有很多收敛机制,最主要的就是分组抑制静默,alertmanager 收到告警之后会先进行分组,然后进入通知队列,这个队列会对通知的邮件进行抑制静默,再根据 router 将告警路由到不同的接收器 机制 说明 分组 (group) 将类似性质的告警合并为单个进行通知 抑制 (Inhibition) 当告警发生后,停止重复发送由此告警引发的其他告警 静默 (Silences) 一种简单的特定时间静音提醒的机制
分组:根据报警名称分组,如果相同的报警名称的信息有多条,会合并到一个邮件里发出。
匹配的报警名称:
prometheus 监控的报警规则
/usr/local/prometheus/rules/*.yml
- alert: 节点挂了
抑制:消除冗余告警,在 alertmanager 中配置的
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['instance']
##当我收到一个告警级别为 critical 时,他就会抑制掉 warning 这个级别的告警,这个告警等级是在你编写规则的时候定义的,最后一行就是要对哪些告警做抑制,通过标签匹配的,我这里只留了一个 instance,举个最简单的例子,当现在 alertmanager 先收到一条 critical、又收到一条 warning 且 instance 值一致的两条告警他的处理逻辑是怎样的。
##在监控 nginx,nginx 宕掉的告警级别为 warning,宿主机宕掉的告警级别为 critical,譬如说现在我跑 nginx 的服务器凉了,这时候 nginx 肯定也凉了,普罗米修斯发现后通知 alertmanager,普罗米修斯发过来的是两条告警信息,一条是宿主机凉了的,一条是 nginx 凉了的,alertmanager 收到之后,发现告警级别一条是 critical,一条是 warning,而且 instance 标签值一致,也就是说这是在一台机器上发生的,所以他就会只发一条 critical 的告警出来,warning 的就被抑制掉了,我们收到的就是服务器凉了的通知
静默:
特定时间静音提醒的机制,主要是使用标签匹配这一批不发送告警,假如某天要对服务器进行维护,可能会涉及到服务器重启,在这期间肯定会有 N 多告警发出来, 在这期间配置一个静默,这类的告警就不要发了
告警示例
监控内存 (node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes )* 100 > 80
编写规则:
CD /usr/local/prometheus/rules
cat memory.yml
groups:
- name: memeory_rules
rules:
- alert: 内存没了
expr: (node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes )* 100 > 80 #表达式成立,即可以查询到数据
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 内存没了"
description: "{{ $labels.instance }} 内存没了,当前使用率为 {{ $value }}"
配置告警分配
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 5m
receiver: 'default-receiver'
routes:
- group_by: ['mysql']
group_wait: 10s
group_interval: 10s
repeat_interval: 5m
receiver: 'mysql-pager'
match_re:
job: mysql
receivers:
- name: 'default-receiver'
email_configs:
- to: 'xxx@xx.com'
- name: 'mysql-pager'
email_configs:
- to: 'xxx@xx.cn'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['instance']
钉钉报警 go版本
编译钉钉webhook接口
#安装go环境
wget -c https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz
tar -C /usr/local/ -zxvf go1.8.3.linux-amd64.tar.gz
mkdir -p /home/gocode
cat << EOF >> /etc/profile
export GOROOT=/usr/local/go #设置为go安装的路径
export GOPATH=/home/gocode #默认安装包的路径
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin
EOF
source /etc/profile
----------------------------------------
#安装钉钉插件
cd /home/gocode/
mkdir -p src/github.com/timonwong/
cd /home/gocode/src/github.com/timonwong/
git clone https://github.com/timonwong/prometheus-webhook-dingtalk.git
cd prometheus-webhook-dingtalk
make
#编译成功
[root@mini-install prometheus-webhook-dingtalk]# make
>> formatting code
>> building binaries
> prometheus-webhook-dingtalk
>> checking code style
>> running tests
? github.com/timonwong/prometheus-webhook-dingtalk/chilog [no test files]
? github.com/timonwong/prometheus-webhook-dingtalk/cmd/prometheus-webhook-dingtalk [no test files]
? github.com/timonwong/prometheus-webhook-dingtalk/models [no test files]
? github.com/timonwong/prometheus-webhook-dingtalk/notifier [no test files]
? github.com/timonwong/prometheus-webhook-dingtalk/template [no test files]
? github.com/timonwong/prometheus-webhook-dingtalk/template/internal/deftmpl [no test files]
? github.com/timonwong/prometheus-webhook-dingtalk/webrouter [no test files]
#创建软连接
ln -s /home/gocode/src/github.com/timonwong/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk /usr/local/bin/prometheus-webhook-dingtalk
##查看
prometheus-webhook-dingtalk --help
usage: prometheus-webhook-dingtalk --ding.profile=DING.PROFILE [<flags>]
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
--web.listen-address=":8060"
The address to listen on for web interface.
--ding.profile=DING.PROFILE ...
Custom DingTalk profile (can be given multiple times, <profile>=<dingtalk-url>).
--ding.timeout=5s Timeout for invoking DingTalk webhook.
--template.file="" Customized template file (see template/default.tmpl for example)
--log.level=info Only log messages with the given severity or above. One of: [debug, info, warn, error]
--version Show application version.
启动钉钉插件
根据已申请的钉钉接口启动钉钉插件
prometheus-webhook-dingtalk --ding.profile="webhook=https://oapi.dingtalk.com/robot/send?access_token=OOOOOOXXXXXXOXOXOX9b46d54e780d43b98a1951489e3a0a5b1c6b48e891e86bd"
#注意:可以配置多个webhook名字,这个名字和后续的报警url相关联
#关于这里的 -ding.profile 参数:为了支持同时往多个钉钉自定义机器人发送报警消息,因此 -ding.profile 可以在命令行中指定多次,比如:
prometheus-webhook-dingtalk \
--ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx" \
--ding.profile="webhook2=https://oapi.dingtalk.com/robot/send?access_token=yyyyyyyyyyy"
这里就定义了两个 WebHook,一个 webhook1,一个 webhook2,用来往不同的钉钉组发送报警消息。
然后在 AlertManager 的配置里面,加入相应的 receiver(注意下面的 url):
receivers:
- name: send_to_dingding_webhook1
webhook_configs:
- send_resolved: false
url: http://localhost:8060/dingtalk/webhook1/send
- name: send_to_dingding_webhook2
webhook_configs:
- send_resolved: false
url: http://localhost:8060/dingtalk/webhook2/send
##配置钉钉插件为系统服务
cat > dingtalk.service <<EFO
[Unit]
Description=alertmanager
[Service]
Restart=on-failure
ExecStart=/usr/local/bin/prometheus-webhook-dingtalk --ding.profile="webhook=https://oapi.dingtalk.com/robot/send?access_token=XXXXXXXXOOOOOOO0d43b98a1951489e3a0a5b1c6b48e891e86bd"
[Install]
WantedBy=multi-user.target
EFO
systemctl daemon-reload
systemctl status dingtalk 会报错,请忽略,直接start dingtalk
##看端口监听
[root@mini-install system]# ss -tanlp | grep 80
LISTEN 0 128 :::8060 :::* users:(("prometheus-webh",pid=18541,fd=3))
##简单测试
curl -H "Content-Type: application/json" -d '{ "version": "4", "status": "firing", "description":"description_content"}' http://localhost:8060/dingtalk/webhook/send
##prometheus webhook 传递数据格式
The webhook receiver allows configuring a generic receiver:
# Whether or not to notify about resolved alerts.
[ send_resolved: <boolean> | default = true ]
# The endpoint to send HTTP POST requests to.
url: <string>
# The HTTP client's configuration.
[ http_config: <http_config> | default = global.http_config ]
The Alertmanager will send HTTP POST requests in the following JSON format to the configured endpoint:
{
"version": "4",
"groupKey": <string>, // key identifying the group of alerts (e.g. to deduplicate)
"status": "<resolved|firing>",
"receiver": <string>,
"groupLabels": <object>,
"commonLabels": <object>,
"commonAnnotations": <object>,
"externalURL": <string>, // backlink to the Alertmanager.
"alerts": [
{
"status": "<resolved|firing>",
"labels": <object>,
"annotations": <object>,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>",
"generatorURL": <string> // identifies the entity that caused the alert
},
...
]
}
alertmanager
配置
wget https://github.com/prometheus/alertmanager/releases/download/v0.19.0/alertmanager-0.19.0.linux-amd64.tar.gz tar zxvf alertmanager-0.19.0.linux-amd64.tar.gz ln -sv `pwd`/alertmanager-0.19.0.linux-amd64 /usr/local/alertmanager #配置为系统服务 cat >> /usr/lib/systemd/system/alertmanager.service <<EFO [Unit] Description=alertmanager [Service] Restart=on-failure ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml [Install] WantedBy=multi-user.target EFO systemctl daemon-reload 后启动 #编辑配置文件 cd /usr/local/alertmanager vim alertmanager.yml global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://localhost:8060/dingtalk/webhook/send'
和prometheus 结合
pwd
/usr/local/prometheus
mkdir rules && cd !$
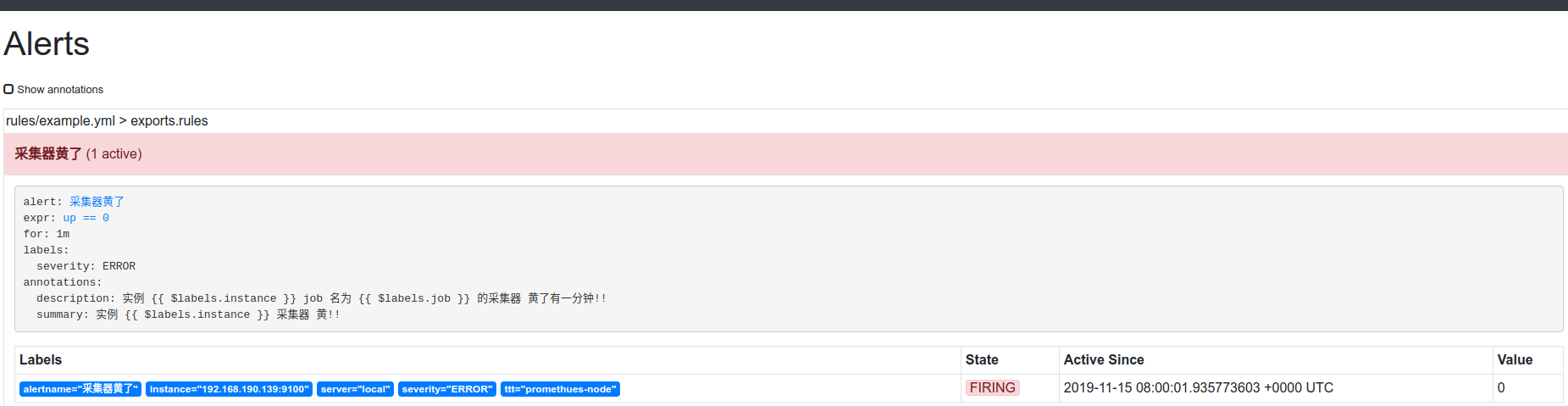
cat example.yml
groups:
- name: exports.rules ##定义这组告警的组名,同性质的,都是监控实例exports是否开启的模板
rules:
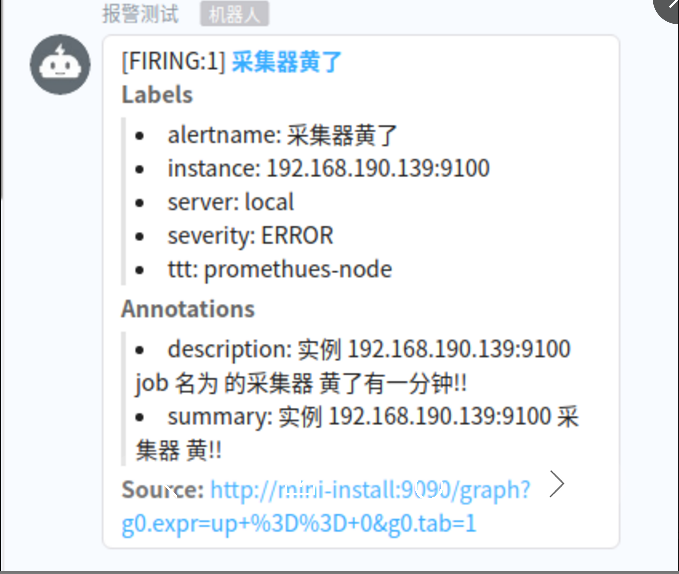
- alert: 采集器黄了 ## 告警名称
expr: up == 0 ## 告警表达式,监控up指标,如果等于0就进行下面的操作
for: 1m ## 持续一分钟为0进行告警
labels: ## 定义告警级别
severity: ERROR
annotations: ## 定义了告警通知怎么写,默认调用了{$labels.instance&$labels.job}的值
summary: "实例 {{ $labels.instance }} 采集器 黄!!"
description: "实例 {{ $labels.instance }} job 名为 {{ $labels.job }} 的采集器 黄了有一分钟!!"
cat prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
##启动服务各个服务
节点监控正常后关闭一个节点。效果