
从3.1版本开始,Lucene和Solr开始在64位的Windows和Solaris系统中默认使用MMapDirectory,从3.3版本开始,64位的Linux系统也启用了这个配置。这个变化使一些Lucene和Solr的用户有些迷茫,因为突然之间他们的系统的某些行为和原来不一样了。在邮件列表中,一些用户发帖询问为什么使用的资源比原来多了很多。也有很多专家开始告诉人们不要使用MMapDirectory。但是从Lucene的commiter的视角来看,MMapDirectory绝对是这些平台的最佳选择。
在这篇blog中,我会试着解释解释关于virtual memory的一些基本常识,以及这些常识是怎么被用于提升lucene的性能。了解了这些,你就会明白那些不让你使用MMapDirectory的人是错误的。第二部分我会列出一些配置的细节,可以避免出现“mmap failed”这样的错误或者由于java堆的一些特性导致lucene无法达到最优的性能。
Virtual Memory[1]
我们从操作系统的内核开始说起。从70年代开始,软件的I/O模式就是这样的:只要你需要访问disk的数据,你就会向kernal发起一个syscall,把一个指向某个buffer的指针传进去,然后读或者写磁盘。如果你不想频繁的发起大量的syscall,(因为用户进程发起syscall会消耗很多资源),你应该使用较大的buffer,这样每次多读一些,访问磁盘的次数也就少了。这也是为什么有人建议把Lucene的整个index都load到Java heap中的一个原因(使用RAMDirectory)。
但是所有的现代操作系统,像Linux,Windows(NT+), Mac OS X, 以及solaris都提供了一个更好的方式来完成I/O:他们用复杂的文件系统cache和内存管理来帮你buffer数据。其中最重要的一个feature叫做Virtual Memory,是一个处理超大数据(比如lucene index)的很好的解决方案。Virtual Memory是计算机体系结构的一个重要部分,实现它需要硬件级的支持,一般称作memory management unit(MMU),是CPU的一部分。它的工作方式非常简单:每个进程都有独立的虚拟地址空间,所有的library,堆,栈空间都映射在这个虚拟空间里。在大多数情况下,这个虚拟地址空间的起始偏移量都是0,在这里load程序代码,因为程序代码的地址指针不会变化。每个进程都会看到一个大的,不间断的先行地址空间,它被称为virtual memory,因为这个地址空间和physical memory没有半毛钱关系,只是进程看起来像memory而已。进程可以像访问真实内存一样访问这个虚拟地址空间,也不需要关心与此同时还有很多其他进程也在使用内存。底层的OS和MMU一起合作,把这些虚拟地址映射到真实的memory中。这个工作需要page table的帮助,page table由位于MMU硬件里的TLBs(translation lookaside buffers, 它cache了频繁被访问的page)支持。这样,OS可以把所有进程的内存访问请求发布到真实可用的物理内存上,而且对于运行的程序来说是完全透明的。
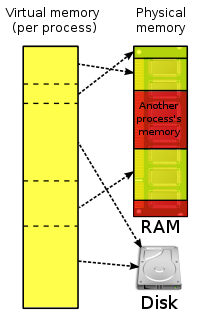
Schematic drawing of virtual memory(image from Wikipedia [1], http://en.wikipedia.org/wiki/File:Virtual_memory.svg, licensed by CC BY-SA 3.0)
{kind=link}
使用了这样的虚拟化之后,OS还需要做一件事:当物理内存不够的时候,OS要能决定swap out一些不再使用的pages,释放物理空间。当一个进程试着访问一个page out的虚拟地址时,它会再次被reload进内存。在这个过程里,用户进程不需要做任何事情,对进程来说,内存管理是完全透明的。这对应用程序来说是天大的好事,因为它不必关心内存是否够用。当然,这对于需要使用大量内存的应用,比如Lucene,也会来带一些问题。
Lucene & Virtual Memory
我们来看一个例子,假设我们把整个的索引load进了内存(其实是virtual memory)。如果我们分配了一个RAMDirectory,并且把所有的索引文件都load进去了,那么我们其实违背了OS的意愿。OS本身是会尽力优化磁盘访问,所以OS会在物理内存中cache住所有的磁盘IO。而我们把这些所有本应cache住的内容copy到了我们自己的虚拟地址空间了,消耗了大量的物理内存。而物理内存是有限的,OS可能会把我们分配的这个超大的RAMDirectory踢出物理内存,也就是放到了磁盘上(OS swap file)。事实上,我们是在和OS kernel打架,结果就是OS把我们辛辛苦苦从磁盘上读取的数据又踢回了磁盘。所以RAMDirectory并不是优化索引加载时耗的好主意。而且,RAMDirectory还有一些和GC以及concurrency相关的问题。因为数据存储在swap space,JAVA的GC要清理它是很费劲的。这会导致大量的磁盘IO,很慢的索引访问速度,以及由于GC不方便而导致的长达数分钟的延迟。
如果我们不用RAMDirectory来缓存index,而是使用NIOFSDirectory或者SimpleFSDirectory,会有另外的问题:我们的代码需要执行很多syscall来拷贝数据,数据流向是从磁盘或文件系统缓存向Java heap的buffer。在每个搜索请求中,这样的IO都存在。
Memory Mapping Files
上面问题的解决方案就是MMapDirectory,它使用virtual memory和mmap来访问磁盘文件。
在本文前半部分讲述的方法,我们都是依赖系统调用在文件系统cache以及Java heap之间拷贝数据。那么怎么才能直接访问文件系统cache呢?这就是mmap的作用!
简单说MMapDirectory就是把lucene的索引当作swap file来处理。mmap()系统调用让OS把整个索引文件映射到虚拟地址空间,这样Lucene就会觉得索引在内存中。然后Lucene就可以像访问一个超大的byte[]数据(在Java中这个数据被封装在ByteBuffer接口里)一样访问磁盘上的索引文件。Lucene在访问虚拟空间中的索引时,不需要任何的系统调用,CPU里的MMU和TLB会处理所有的映射工作。如果数据还在磁盘上,那么MMU会发起一个中断,OS将会把数据加载进文件系统Cache。如果数据已经在cache里了,MMU/TLB会直接把数据映射到内存,这只需要访问内存,速度很快。程序员不需要关心paging in/out,所有的这些都交给OS。而且,这种情况下没有并发的干扰,唯一的问题就是Java的ByteBuffer封装后的byte[]稍微慢一些,但是Java里要想用mmap就只能用这个接口。还有一个很大的优点就是所有的内存issue都由OS来负责,这样没有GC的问题。
What does this all mean to our Lucene/Solr application?
- 为了不和OS争内存,应该给JVM分尽可能少的heap空间(-Xmx option). 索引的访问全部都交给OS cache。而且这样对JVM的GC也好。
- 释放尽可能多的内存给OS,这样文件系统缓存的空间也大,swap的概率低。
—————————————————————-
Don’t be afraid – Some clarification to common misunderstandings
Since version 3.1, Apache Lucene and Solr use MMapDirectory by default on 64bit Windows and Solaris systems; since version 3.3 also for 64bit Linux systems. This change lead to some confusion among Lucene and Solr users, because suddenly their systems started to behave differently than in previous versions. On the Lucene and Solr mailing lists a lot of posts arrived from users asking why their Java installation is suddenly consuming three times their physical memory or system administrators complaining about heavy resource usage. Also consultants were starting to tell people that they should not use MMapDirectory and change their solrconfig.xml to work instead with slow SimpleFSDirectory or NIOFSDirectory (which is much slower on Windows, caused by a JVM bug #6265734). From the point of view of the Lucene committers, who carefully decided that using MMapDirectory is the best for those platforms, this is rather annoying, because they know, that Lucene/Solr can work with much better performance than before. Common misinformation about the background of this change causes suboptimal installations of this great search engine everywhere.
In this blog post, I will try to explain the basic operating system facts regarding virtual memory handling in the kernel and how this can be used to largely improve performance of Lucene(“VIRTUAL MEMORY for DUMMIES”). It will also clarify why the blog and mailing list posts done by various people are wrong and contradict the purpose of MMapDirectory. In the second part I will show you some configuration details and settings you should take care of to prevent errors like “mmap failed” and suboptimal performance because of stupid Java heap allocation.
Virtual Memory[1]
Let’s start with your operating system’s kernel: The naive approach to do I/O in software is the way, you have done this since the 1970s – the pattern is simple: whenever you have to work with data on disk, you execute a syscall to your operating system kernel, passing a pointer to some buffer (e.g. a byte[] array in Java) and transfer some bytes from/to disk. After that you parse the buffer contents and do your program logic. If you don’t want to do too many syscalls (because those may cost a lot processing power), you generally use large buffers in your software, so synchronizing the data in the buffer with your disk needs to be done less often. This is one reason, why some people suggest to load the whole Lucene index into Java heap memory (e.g., by using RAMDirectory).
But all modern operating systems like Linux, Windows (NT+), MacOS X, or Solaris provide a much better approach to do this 1970s style of code by using their sophisticated file system caches and memory management features. A feature called “virtual memory” is a good alternative to handle very large and space intensive data structures like a Lucene index. Virtual memory is an integral part of a computer architecture; implementations require hardware support, typically in the form of a memory management unit (MMU) built into the CPU. The way how it works is very simple: Every process gets his own virtual address space where all libraries, heap and stack space is mapped into. This address space in most cases also start at offset zero, which simplifies loading the program code because no relocation of address pointers needs to be done. Every process sees a large unfragmented linear address space it can work on. It is called “virtual memory” because this address space has nothing to do with physical memory, it just looks like so to the process. Software can then access this large address space as if it were real memory without knowing that there are other processes also consuming memory and having their own virtual address space. The underlying operating system works together with the MMU (memory management unit) in the CPU to map those virtual addresses to real memory once they are accessed for the first time. This is done using so called page tables, which are backed by TLBslocated in the MMU hardware (translation lookaside buffers, they cache frequently accessed pages). By this, the operating system is able to distribute all running processes’ memory requirements to the real available memory, completely transparent to the running programs. By using this virtualization, there is one more thing, the operating system can do: If there is not enough physical memory, it can decide to “swap out” pages no longer used by the processes, freeing physical memory for other processes or caching more important file system operations. Once a process tries to access a virtual address, which was paged out, it is reloaded to main memory and made available to the process. The process does not have to do anything, it is completely transparent. This is a good thing to applications because they don’t need to know anything about the amount of memory available; but also leads to problems for very memory intensive applications like Lucene.
Lucene & Virtual Memory
Let’s take the example of loading the whole index or large parts of it into “memory” (we already know, it is only virtual memory). If we allocate a RAMDirectory and load all index files into it, we are working against the operating system: The operating system tries to optimize disk accesses, so it caches already all disk I/O in physical memory. We copy all these cache contents into our own virtual address space, consuming horrible amounts of physical memory (and we must wait for the copy operation to take place!). As physical memory is limited, the operating system may, of course, decide to swap out our large RAMDirectory and where does it land? – On disk again (in the OS swap file)! In fact, we are fighting against our O/S kernel who pages out all stuff we loaded from disk [2]. So RAMDirectory is not a good idea to optimize index loading times! Additionally, RAMDirectory has also more problems related to garbage collection and concurrency. Because the data residing in swap space, Java’s garbage collector has a hard job to free the memory in its own heap management. This leads to high disk I/O, slow index access times, and minute-long latency in your searching code caused by the garbage collector driving crazy.
On the other hand, if we don’t use RAMDirectory to buffer our index and useNIOFSDirectory or SimpleFSDirectory, we have to pay another price: Our code has to do a lot of syscalls to the O/S kernel to copy blocks of data between the disk or filesystem cache and our buffers residing in Java heap. This needs to be done on every search request, over and over again.
Memory Mapping Files
The solution to the above issues is MMapDirectory, which uses virtual memory and a kernel feature called “mmap” [3] to access the disk files.
In our previous approaches, we were relying on using a syscall to copy the data between the file system cache and our local Java heap. How about directly accessing the file system cache? This is what mmap does!
Basically mmap does the same like handling the Lucene index as a swap file. The mmap()syscall tells the O/S kernel to virtually map our whole index files into the previously described virtual address space, and make them look like RAM available to our Lucene process. We can then access our index file on disk just like it would be a large byte[] array (in Java this is encapsulated by a ByteBuffer interface to make it safe for use by Java code). If we access this virtual address space from the Lucene code we don’t need to do any syscalls, the processor’s MMU and TLB handles all the mapping for us. If the data is only on disk, the MMU will cause an interrupt and the O/S kernel will load the data into file system cache. If it is already in cache, MMU/TLB map it directly to the physical memory in file system cache. It is now just a native memory access, nothing more! We don’t have to take care of paging in/out of buffers, all this is managed by the O/S kernel. Furthermore, we have no concurrency issue, the only overhead over a standard byte[] array is some wrapping caused by Java’s ByteBufferinterface (it is still slower than a real byte[] array, but that is the only way to use mmap from Java and is much faster than all other directory implementations shipped with Lucene). We also waste no physical memory, as we operate directly on the O/S cache, avoiding all Java GC issues described before.
What does this all mean to our Lucene/Solr application?
- We should not work against the operating system anymore, so allocate as less as possible heap space (-Xmx Java option). Remember, our index accesses rely on passed directly to O/S cache! This is also very friendly to the Java garbage collector.
- Free as much as possible physical memory to be available for the O/S kernel as file system cache. Remember, our Lucene code works directly on it, so reducing the number of paging/swapping between disk and memory. Allocating too much heap to our Lucene application hurts performance! Lucene does not require it with MMapDirectory.
Why does this only work as expected on operating systems and Java virtual machines with 64bit?
One limitation of 32bit platforms is the size of pointers, they can refer to any address within 0 and 232-1, which is 4 Gigabytes. Most operating systems limit that address space to 3 Gigabytes because the remaining address space is reserved for use by device hardware and similar things. This means the overall linear address space provided to any process is limited to 3 Gigabytes, so you cannot map any file larger than that into this “small” address space to be available as bigbyte[] array. And when you mapped that one large file, there is no virtual space (address like “house number”) available anymore. As physical memory sizes in current systems already have gone beyond that size, there is no address space available to make use for mapping files without wasting resources (in our case “address space”, not physical memory!).
On 64bit platforms this is different: 264-1 is a very large number, a number in excess of 18 quintillion bytes, so there is no real limit in address space. Unfortunately, most hardware (the MMU, CPU’s bus system) and operating systems are limiting this address space to 47 bits for user mode applications (Windows: 43 bits) [4]. But there is still much of addressing space available to map terabytes of data.
Common misunderstandings
If you have read carefully what I have told you about virtual memory, you can easily verify that the following is true:
- MMapDirectory does not consume additional memory and the size of mapped index files is not limited by the physical memory available on your server. By mmap() files, we only reserve address space not memory! Remember, address space on 64bit platforms is for free!
- MMapDirectory will not load the whole index into physical memory. Why should it do this? We just ask the operating system to map the file into address space for easy access, by no means we are requesting more. Java and the O/S optionally provide the option to try loading the whole file into RAM (if enough is available), but Lucene does not use that option (we may add this possibility in a later version).
- MMapDirectory does not overload the server when “top” reports horrible amounts of memory. “top” (on Linux) has three columns related to memory: “VIRT”, “RES”, and “SHR”. The first one (VIRT, virtual) is reporting allocated virtual address space (and that one is for free on 64 bit platforms!). This number can be multiple times of your index size or physical memory when merges are running in IndexWriter. If you have only one IndexReader open it should be approximately equal to allocated heap space (-Xmx) plus index size. It does not show physical memory used by the process. The second column (RES, resident) memory shows how much (physical) memory the process allocated for operating and should be in the size of your Java heap space. The last column (SHR, shared) shows how much of the allocated virtual address space is shared with other processes. If you have several Java applications using MMapDirectory to access the same index, you will see this number going up. Generally, you will see the space needed by shared system libraries, JAR files, and the process executable itself (which are also mmapped).
How to configure my operating system and Java VM to make optimal use of MMapDirectory?
First of all, default settings in Linux distributions and Solaris/Windows are perfectly fine. But there are some paranoid system administrators around, that want to control everything (with lack of understanding). Those limit the maximum amount of virtual address space that can be allocated by applications. So please check that “ulimit -v” and “ulimit -m” both report “unlimited”, otherwise it may happen that MMapDirectory reports “mmap failed” while opening your index. If this error still happens on systems with lot’s of very large indexes, each of those with many segments, you may need to tune your kernel parameters in /etc/sysctl.conf: The default value of vm.max_map_count is 65530, you may need to raise it. I think, for Windows and Solaris systems there are similar settings available, but it is up to the reader to find out how to use them.
For configuring your Java VM, you should rethink your memory requirements: Give only the really needed amount of heap space and leave as much as possible to the O/S. As a rule of thumb: Don’t use more than ¼ of your physical memory as heap space for Java running Lucene/Solr, keep the remaining memory free for the operating system cache. If you have more applications running on your server, adjust accordingly. As usual the more physical memory the better, but you don’t need as much physical memory as your index size. The kernel does a good job in paging in frequently used pages from your index.
A good possibility to check that you have configured your system optimally is by looking at both “top” (and correctly interpreting it, see above) and the similar command “iotop” (can be installed, e.g., on Ubuntu Linux by “apt-get install iotop”). If your system does lots of swap in/swap out for the Lucene process, reduce heap size, you possibly used too much. If you see lot’s of disk I/O, buy more RUM (Simon Willnauer) so mmapped files don’t need to be paged in/out all the time, and finally: buy SSDs.
Happy mmapping!